
Fehlermaßnahmen bei Massenspeichern
Bei Massenspeichern werden im Interesse hoher Speicherdichten und Übertragungsraten sowie kurzer Zugriffszeiten die zugrundeliegenden physikalischen Effekte soweit ausgenutzt, wie dies technisch – in der Massenfertigung – überhaupt möglich ist. Während man die mechanische Präzision praktisch in vollem Umfang gewährleisten kann (Ausschuss kommt gar nicht erst zur Auslieferung), sind es kleinste Fehler im Speichermedium (manchmal auch Verunreinigungen oder äußerliche Beschädigungen, z. B. bei Disketten) und kleinste zeitweilige Abweichungen während des Betriebs (z. B. ungenaues Positionieren auf Grund von Erschütterungen), die entsprechende Fehlermaßnahmen erforderlich machen. Hierbei handelt es sich um einen Verbund aus mehreren Verfahren: (1) Ausblenden fehlerhafter Sektoren oder Spuren (Bad Sectors/Tracks) und Umleiten auf Reservesektoren bzw. -spuren (Defektverwaltung), (2) Fehlerkorrektur, (3) Wiederholen von Zugriffen (Retry).
Defektverwaltung (Defect Management)
Magnetische Speichermedien kann man praktisch nicht vollkommen fehlerfrei fertigen. Der Hersteller überlässt deshalb nicht die gesamte Oberfläche des Speichermediums dem Anwender, sondern hält einen gewissen Anteil als Ausfallreserve zurück (Reservesektoren bzw. Reservespuren). Beispiel: für je 64k Sektoren sind 32 Reservesektoren vorgesehen.
Die Defektliste
Der Hersteller unterzieht jedes Speichermedium einer gründlichen Oberflächenanalyse. Als defekt erkannte Sektoren werden in einer Defektliste vermerkt, die in gesonderten, dem Anwender unzugänglichen Spuren gespeichert wird. Den defekten Sektoren werden Reservesektoren zugewiesen.
Primäre Defekte (Primary Defects)
Dies sind jene Defekte, die der Hersteller bei der Oberflächenanalyse festgestellt hat.
Hinzugekommene Defekte (Grown Defects)
Während des Betriebs deklariert der Controller des Laufwerks Sektoren, die durch unkorrigierbare Lesefehler auffallen, als defekt und weist ihnen (solange Vorrat reicht) Reservesektoren zu.
Fehlerkorrektur
Die Sektoren enthalten eine bestimmte (hersteller- oder modellspezifische) Anzahl an Fehlerkorrekturbytes (ECC-Bytes). Man ist bestrebt, vor allem Fehler in aufeinanderfolgenden Datenbitpositionen (Bündelfehler; Burst Errors) zu korrigieren. Das ist das typische Fehlerbild einer Beschädigung der Oberfläche. So wird z. B. ein Kratzer mehrere aufeinanderfolgende Bits unbrauchbar machen. Dass beliebig verstreute einzelne Bits fehlerhaft sind, ist demgegenüber viel weniger wahrscheinlich.
Herkömmliche Korrekturverfahren
Man verwendet sog. zyklische Codes. Ein solcher Code ist in der Lage, einen einzelnen Bündelfehler einer bestimmten Länge zu korrigieren. Die korrigierbare Länge reicht typischerweise von 3 bis 15 Bits.
Korrekturverfahren moderner Laufwerke
Man verwendet (1) wirksamere Codes und unterwirft (2) die Daten des jeweiligen Sektors mehreren ineinander verschachtelten Kontrollen. Die folgende Abbildung veranschaulicht dies anhand eines Beispiels. An die 512 Datenbytes (d1…d512) werden insgesamt 28 Kontrollbytes angehängt, nämlich 24 ECC-Bytes (ecc1…ecc24) und 4 Bytes, die zur Gegenkontrolle (Cross Checking) dienen (xc1…xc4). Die Gegenkontrolle soll die Wahrscheinlichkeit fälschlicher Korrekturen verringern. Die zugehörigen Bytes (xc1…xc4) der Gegenkontrolle werden nach einem anderen Code gebildet als die ECC-Bytes. Sie betreffen alle 512 Datenbytes.
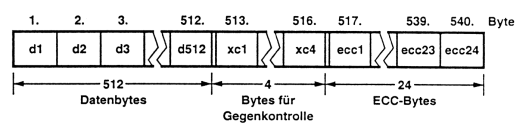
Zum Korrekturvermögen
Die anhand der Abbildung vorgestellten Maßnahmen können bis zu 96 Bits in einem Sektor korrigieren. U. a. kann jeder einfache Burst-Fehler in 4 aufeinanderfolgenden Bytes korrigiert werden.
Korrekturabläufe
Manche Fehler lassen sich während der Datenübertragung (vom Laufwerk zur Interfacesteuerung) korrigieren („on the fly”). Das betrifft u. a. alle einfachen und verschiedene zweifache Burst-Fehler. Andere Fehler erfordern ausgedehntere Korrekturabläufe (die vom Mikrocontroller des Laufwerks ausgeführt werden).
Zugriffswiederholung (Retry)
Ehe der Controller einen recht langwierigen Korrekturablauf beginnt, versucht er, den Sektor nochmals zu lesen. Die Anzahl der Zugriffswiederholungen (Number of Retries) ist programmseitig einstellbar.
Eine typische Verfahrensweise:
- Werden bei der Zugriffswiederholung korrekte Daten gelesen, so handelt es sich um einen flüchtigen (transienten) Fehler und nicht um einen Defekt des Speichermediums.
- Ergeben sich bei der Zugriffswiederholung in 2 aufeinanderfolgenden Zugriffen die gleichen Fehleranzeichen, so wird zunächst eine Fehlerkorrektur versucht (manche Laufwerke können z. B. bis zu drei Burst-Fehler in einem Sektor korrigieren).
- Schwere Fehler (z. B. korrigierbare dreifache Burst-Fehler oder unkorrigierbare Fehler) werden als Defekt des Speichermediums gewertet. Der betroffene Sektor wird durch einen Reservesektor ersetzt.